Microservice transient data
You can use Neptune DXP’s native database integration to address the need to persist a range of microservice specific ephemeral or configuration data:
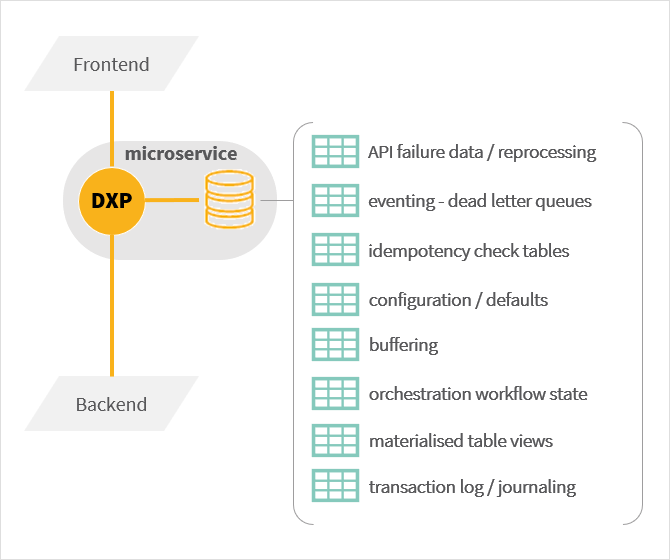
-
API failure data/reprocessing: You can record incoming bad API requests or errors encountered when constructing API responses to evaluate them or to trigger their re-processing.
-
Eventing: Dead letter queues if you implement an asynchronous communication mechanism (for example, event streams or message queues) between Neptune DXP microservices (or other systems) you can record failed events or messages in a Neptune DXP table. This allows you to review the errors to act on them or issue alerts. A periodic job can be used to wipe processed errors.
-
Idempotency check tables. All POST and PATCH and DELETE REST API requests should ideally implement idempotency checks, or risk processing the same request multiple times. You can implement such a check for your microservice APIs by using the following pattern:
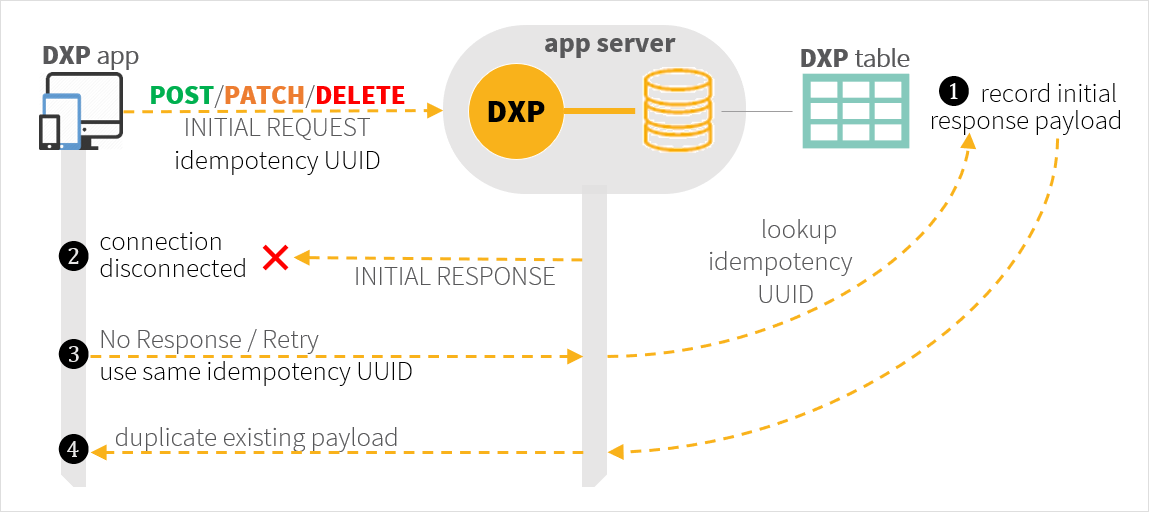
Your API requests must include a unique identifier (for example, a UUID) in an API header (for example, x-idempotency-key). Each time a request is processed the identifier is recorded in a dedicated Neptune DXP Table along with the response composed for the request. If a retry request is made due to a connection failure, using the same idempotency identifier as the initial request, the Neptune DXP microservice can re-issue the original response that failed to reach the client and stop altering the state of the resource again.
-
Configuration options/defaults that control a Neptune DXP’s microservice internal operation need to be persisted for ongoing reference can be easily stored in Neptune DXP table allowing you to recall it during processing. If you prefer the use of JSON data structures Neptune DXP table can record JSON objects eliminating the need for local file processing.
-
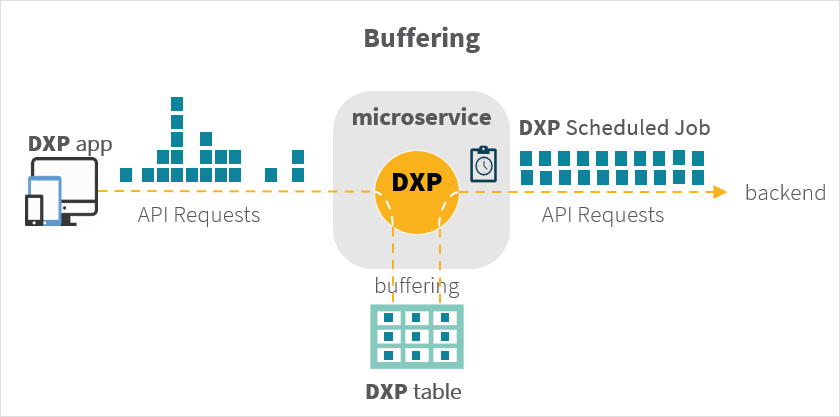
Buffering can be used to normalise abnormal and/or erratic volumes of API requests from clients or other services, which can overload the backend when processed synchronously. If processing can be asynchronous the requests can be staged in a Neptune DXP table in the application server and a periodic job can then batch them to smooth over delivery to the backend.
-
orchestration workflow state: Neptune DXP workflows record their execution state but if you need to persist additional data specific to your use case you can use Neptune DXP tables. The table record ID holding your data must be stored in the Neptune DXP workflow state (essentially a JSON structure), which then allows you to recall it across different script tasks.
-
Materialised table views can be used to support efficient querying and data extraction to improve performance in complex microservice architectures by acting as a form of long term cache. For example, the Customer microservice below supports an
/orderssub-endpoint to allow convenience queries to show the status of a customer’s orders. A Neptune DXP table can be used to host order data received as an asynchronous event: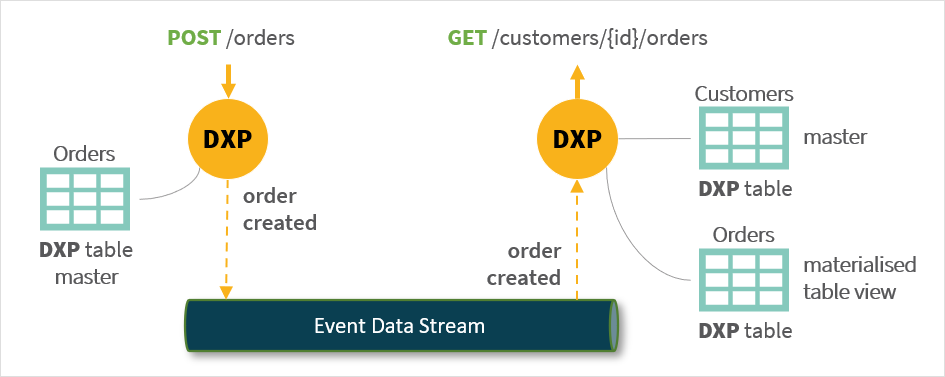
The alternative approach would be a asynchronous REST API call from the customer services to the Order service to get the customer’s orders. Another method would be for the client to orchestrate the collection of data from both services. Both synchronous approaches suffer from latency and punish the landscape with too many requests.
-
Transaction log/journaling when using a Neptune DXP microservice as the system of record for a resource (for example, customer appointments) you will only capture the current state after the API operation is completed. For example, an appointment change from 15:00 AM to 16:00 AM will be successfully reflected in an appointments Neptune DXP table. However, the history of the change will be lost. To mitigate this journal tables recording all API operation need to be kept:
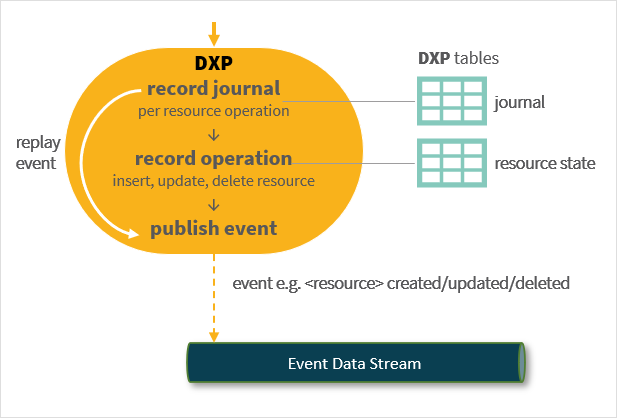
This then provides you with a complete log of the transaction allowing to reconstruct the timeline of events for audit purposes and mitigates data mutation anxiety. The use of journals can also be used as the data source to generate asynchronous events (for example, an appointment created) in an event-driven communications architecture. When failures occur, you can revisit the log of actions in the journal and attempt to retry an operation.