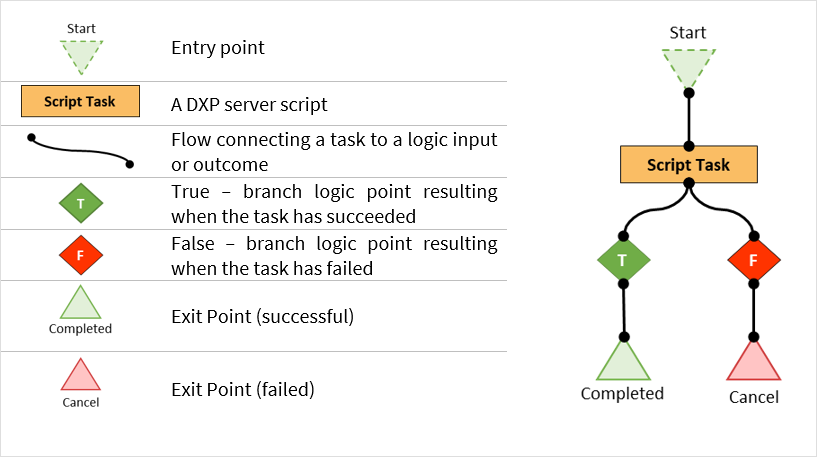
Microservice workflows
Neptune DXP’s Workflow Engine provides a set of elements to help you define a task-driven workflow.
Neptune DXP workflows record their transient state in a dedicated workflow structure. You can describe the data input and output schemas specific to each workflow task using a JSON based notation:
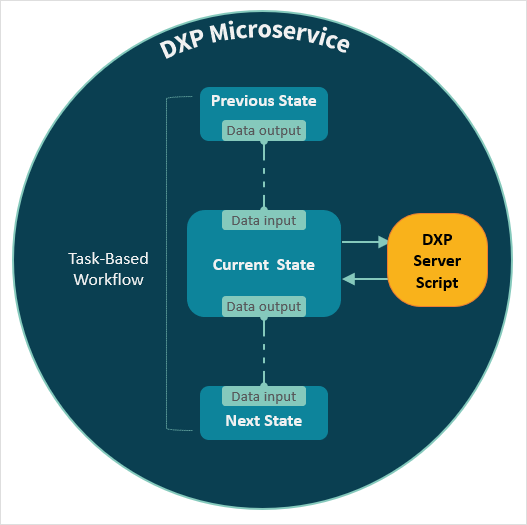
Whilst each schema must be specified separately when implemented they must be aggregated under Neptune DXP’s workflow data structure that moves along during the workflow’s execution. Supporting elements should ideally include an error structure to record exceptions and a key/value metadata structure for use case-specific data. The server script associated with a workflow task must receive the full workflow state and then filter for the task’s specific data input structure. Similarly, the script must alter the task’s specific data output structure and alter the workflow state upon completion.
A common example of a task-based workflow implementation is that of a microservice’s service interface. Consider a customer microservice with the following API methods (omitting any domain/path prefixes for simplicity):
-
POST /customers
-
PUT /customers/{id}
-
DELETE /customers/{id}
-
GET /customers/
-
GET /customers/{id}
-
GET /customers/log
Focusing on a single operation (for example, POST /customers) we can define a dedicate Neptune DXP workflow as the organising mechanism to coordinate the handling of the API request into the microservice and the compilation of the results into a response:
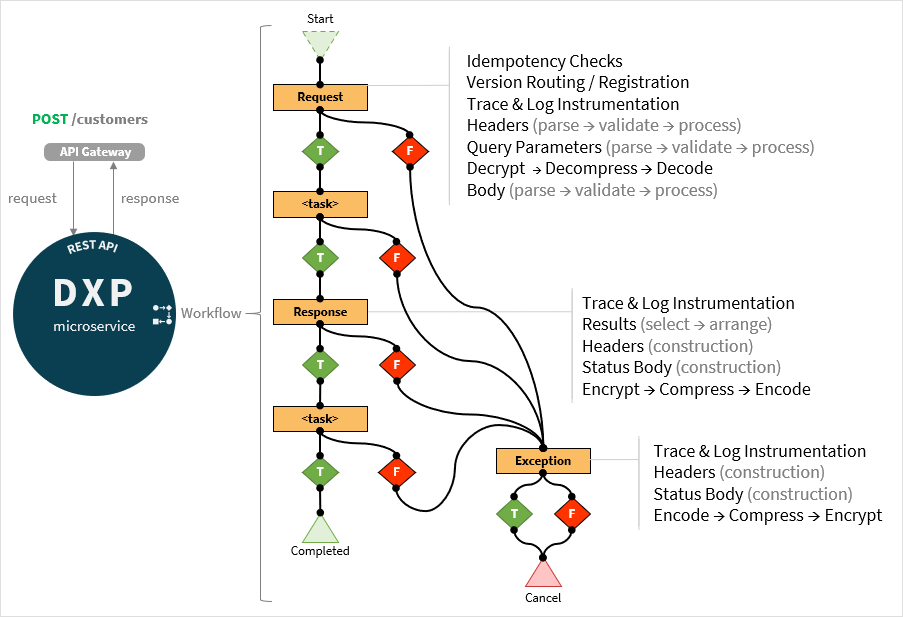
The main elements of this workflow are :
-
Request Task that handles a formatted REST API request in order to perform an operation tackling tasks such as:
-
Idempotency Checks to reduce the risk of processing the same request multiple times.
-
Version Routing / Registration for version less APIs containing the version in a header.
-
Trace & Log Instrumentation to emit information as part of an observability strategy.
-
Headers (parse → validate → process).
-
Query Parameters (parse → validate → process) by querying your database or backend.
-
Decrypt → Decompress → Decode the request body content.
-
Body (parse → validate → process) and populate into internal data structures.
-
-
Pre-Response Component Tasks invoking use case-specific server scripts to carry out the detailed work that will lead to the formulation of a response data set.
-
Response Task processing the resulting data set applying the selection and arrangement rules supplied in the request’s query parameters, after which, it formulates the response’s headers, status and body and finally encrypts, compresses and encodes its content.
-
Post-Response Component Tasks invoking use case-specific server scripts to carry out the detailed work of persisting and/or logging the updates to a resource and eventually publishing as an event to an Event Stream for asynchronous processing by subscribed microservices.
-
Exception Task implementing a generalised exception handling mechanism leading to the formulation of an error response.
The above sub-tasks e.g. idempotency checks are complex activities and, you may need to create a more comprehensive workflow to further compartmentalise each step. The need for these additional tasks, and therefore complexity, further reinforces the value of task-based workflows to organise your implementations.